.png)

If you have not read the blog yet, it summarizes and highlights some key insights from the AWS (Amazon Web Services) Summit I attended in Stockholm this May 2023. I wanted to focus on the talks while there, rather than taking notes, so I decided to record the talks to process them later.
Recording at the Summit
Initially I was unsure of whether recording was allowed, but after talking with AWS personnel, I was assured that it was permissible. I took the recordings themselves on my Android phone with a recording app that I let run in the background so I could take pictures at the same time. I’m not sure, but I suspect this may have had some effect on the performance of the phone, since many pictures came out blurry, as if the camera software had been slow to take the pictures, despite the lighting being ok. Next time I will bring a proper camera.
Post processing
After the summit, I offloaded the mp3 recordings to my computer. I had decided to use generative AI for summarizing the talks, so I had to convert the recordings to text first. At first, I attempted to do this with Microsoft Word dictation feature and the AWS Transcribe service but neither of these provides a good enough result.
It was time to bring out the big guns. I launched a c6a.8xlarge AWS EC2 instance and installed OpenAI Whisper. Using the small model and all 32 cores, I was able to get very good transcripts of all ~5 h of recordings in under 2 hours. I did try a couple of other instance types but decided the process was too slow, I was also unable to get the full performance of GPU acceleration, mainly because I was too lazy to start writing Python.
Writing the posts
This is where things got tricky. I was hellbent on using ChatGPT (GPT-4) to extract insights and other information from the transcripts, but this proved to be more challenging than I initially thought. The first challenge was the 3000-word limit of ChatGPT input. For the Partner Summit texts, I split up the transcripts to an appropriate, yet arbitrary, 2500 words where necessary and prompted these texts similarly.
The blog about the actual Summit day was constructed in a little bit of a different manner: I copied the transcripts into a document with headings for each transcript and saved it as a PDF file in Google drive and proceeded to prompt ChatGPT about it using thethe AskYourPDF plugin.
Crafting the prompts was a challenge in itself. Although most prompts seemed to yield reasonable results, I ended up using a couple of different prompts and combining the output from each for a better result. I also used the PromptPerfect site to generate a better prompt for use with ChatGPT.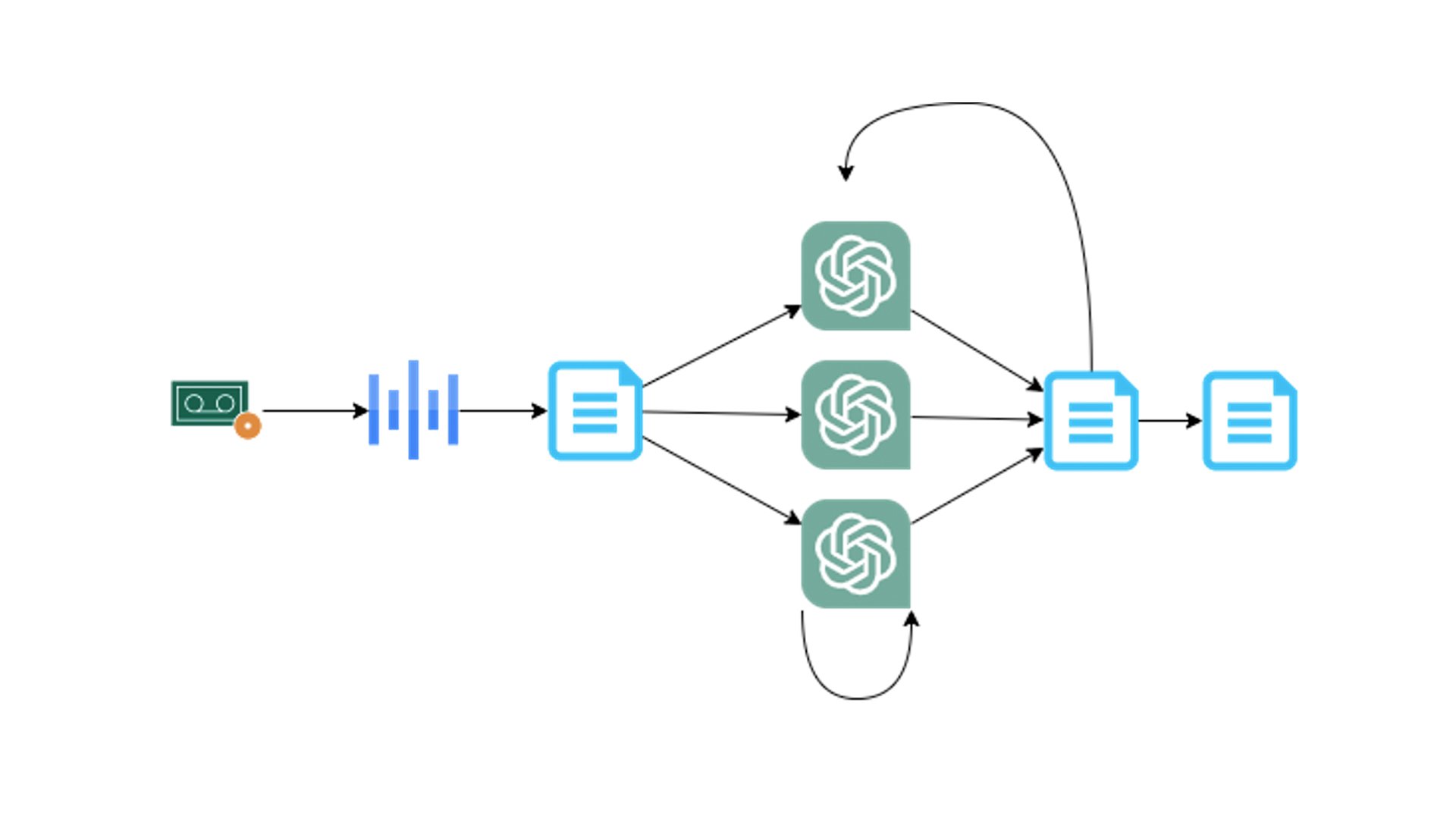
From audio recordings to blog via Whisper and ChatGPT.
In order to achieve satisfactory outcomes, I needed to repeatedly go through the prompt format. When I was satisfied with the output, I collected it and fed it back into a new session to generate the blog text. For the second blog, I was able to use a single session with multiple prompts for the same pdf to get a decent output. I then combined some of the best outputs and proceeded with proofreading and other minor amends. Among other things I needed to check were speaker names, which were mostly incorrectly transcribed.
In the end, I give the write-ups a 3.5/5 score. They are quite informative, but also a bit bland. I think I may have been able to get some more life into it with better prompts, but I had to draw the line somewhere.
Written by:
Frans Ojala, Lead Cloud Architect at Siili
